 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTP-LX: Can LLMs Evaluate Toxicity in Multilingual Scenarios?
Apr 22, 2024



Large language models (LLMs) and small language models (SLMs) are being adopted at remarkable speed, although their safety still remains a serious concern. With the advent of multilingual S/LLMs, the question now becomes a matter of scale: can we expand multilingual safety evaluations of these models with the same velocity at which they are deployed? To this end we introduce RTP-LX, a human-transcreated and human-annotated corpus of toxic prompts and outputs in 28 languages. RTP-LX follows participatory design practices, and a portion of the corpus is especially designed to detect culturally-specific toxic language. We evaluate seven S/LLMs on their ability to detect toxic content in a culturally-sensitive, multilingual scenario. We find that, although they typically score acceptably in terms of accuracy, they have low agreement with human judges when judging holistically the toxicity of a prompt, and have difficulty discerning harm in context-dependent scenarios, particularly with subtle-yet-harmful content (e.g. microagressions, bias). We release of this dataset to contribute to further reduce harmful uses of these models and improve their safe deployment.
A Bootstrap Approach to Automatically Generating Lexical Transfer Rules
Jul 09, 1999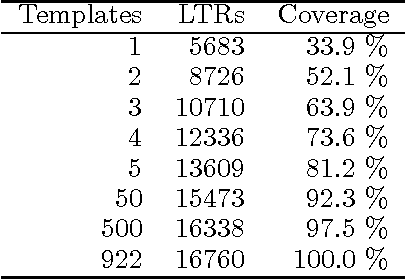
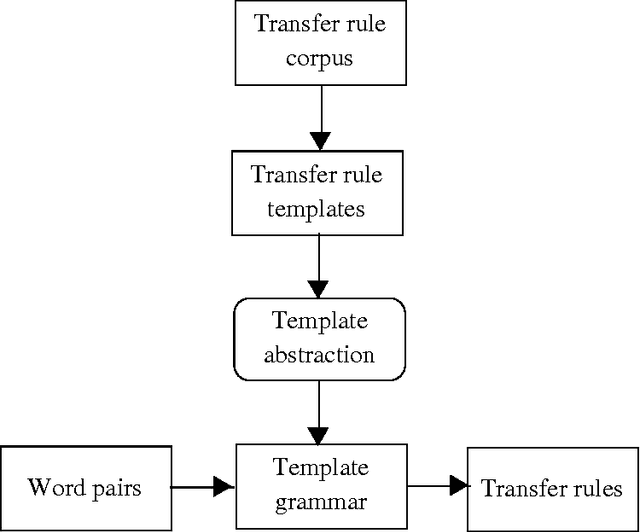

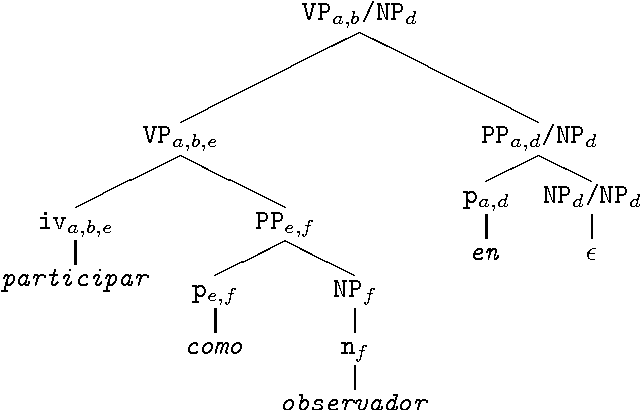
We describe a method for automatically generating Lexical Transfer Rules (LTRs) from word equivalences using transfer rule templates. Templates are skeletal LTRs, unspecified for words. New LTRs are created by instantiating a template with words, provided that the words belong to the appropriate lexical categories required by the template. We define two methods for creating an inventory of templates and using them to generate new LTRs. A simpler method consists of extracting a finite set of templates from a sample of hand coded LTRs and directly using them in the generation process. A further method consists of abstracting over the initial finite set of templates to define higher level templates, where bilingual equivalences are defined in terms of correspondences involving phrasal categories. Phrasal templates are then mapped onto sets of lexical templates with the aid of grammars. In this way an infinite set of lexical templates is recursively defined. New LTRs are created by parsing input words, matching a template at the phrasal level and using the corresponding lexical categories to instantiate the lexical template. The definition of an infinite set of templates enables the automatic creation of LTRs for multi-word, non-compositional word equivalences of any cardinality.
Explanation-based Learning for Machine Translation
Jul 06, 1999
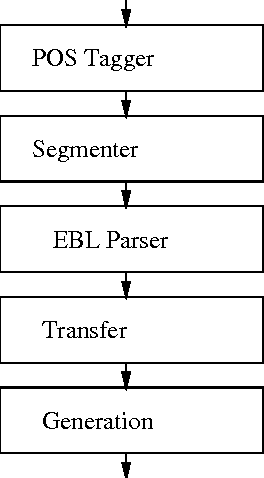

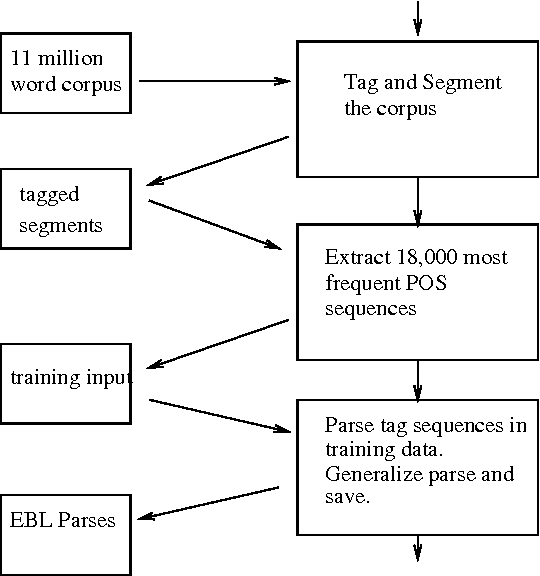
In this paper we present an application of explanation-based learning (EBL) in the parsing module of a real-time English-Spanish machine translation system designed to translate closed captions. We discuss the efficiency/coverage trade-offs available in EBL and introduce the techniques we use to increase coverage while maintaining a high level of space and time efficiency. Our performance results indicate that this approach is effective.
A Unified Example-Based and Lexicalist Approach to Machine Translation
Jun 30, 1999We present an approach to Machine Translation that combines the ideas and methodologies of the Example-Based and Lexicalist theoretical frameworks. The approach has been implemented in a multilingual Machine Translation system.
Automatically Creating Bilingual Lexicons for Machine Translation from Bilingual Text
Jul 20, 1998


A method is presented for automatically augmenting the bilingual lexicon of an existing Machine Translation system, by extracting bilingual entries from aligned bilingual text. The proposed method only relies on the resources already available in the MT system itself. It is based on the use of bilingual lexical templates to match the terminal symbols in the parses of the aligned sentences.
* Latex file, uses colacl.sty file, 7 pages
A Lexicalist Approach to the Translation of Colloquial Text
Jun 18, 1997


Colloquial English (CE) as found in television programs or typical conversations is different than text found in technical manuals, newspapers and books. Phrases tend to be shorter and less sophisticated. In this paper, we look at some of the theoretical and implementational issues involved in translating CE. We present a fully automatic large-scale multilingual natural language processing system for translation of CE input text, as found in the commercially transmitted closed-caption television signal, into simple target sentences. Our approach is based on the Whitelock's Shake and Bake machine translation paradigm, which relies heavily on lexical resources. The system currently translates from English to Spanish with the translation modules for Brazilian Portuguese under development.
* 11 pages, LaTeX, uses tmi.sty